Update on State of Json-parsing Performance
(22-Feb-2009, NOTE: there is an update to this update with even more up-to-date results!)
It has been good year and a half since I blogged about Json performance
("More
on JSON performance in Java (or lack thereof)" ).
So it is
about time to revisit the question and see what is the state of the art
with Java Json processing today.
This time I will be using a bit more full-featured performance benchmark
framework: (codename "StaxBind"), which is based on Japex,
and allows for easy comparison of different data format / library
combination for different tasks. Initially aimed at comparing data
binding performance for xml processing (hence the name), it is growing
for a more general purpose data format processing performance testing
framework.
For now the module is available from Woodstox
repository, and contains a few test cases including one used here.
Since benchmarks are run using Japex the results should be more informative as well as reproduceable; plus, we get some pretty graphs to look at.
1. Test case: "json-field-count"
The specific test used from StaxBind is "json-count", test designed to
allow testing a wide selection of available Java Json parsers. Test code
essentially traverses through given Json documents, counting instances
of field names; results are verified before each test to ensure that all
parsers (or rather, test drivers for parsers) see the same data.
This
traversal operation is not an overly meaningful in itself, but it is
easy to implement for most parsers (see below for exceptions), and
should be reasonably fair and representative regarding expected
processing performance. The other more obvious choice would be a data
binding test -- I hope to cover that later on -- but that will mean
writing much more test code for packages that do not support automatic
data binding.
2. Sample documents
For testing I chose 3 different Json documents:
- Sample #4 from json.org example docs section (the one with "web-app" struct)
- Sample Twitter search response message
- "db100.xml" (from XMLTest document set) automatically converted to json
Document sizes vary from 3 to 15 kB; fairly small, but enough to show the trend about parsing performance. This is not a great set of documents to use, but since there is generally accepted set of Json test documents available (or if there is, please let me know!), it will have to do.
3. Parsers compared
I decided to choose parsers to test from json.org's java parser implementation list. I think that is the most likely starting point for developers; and it is reasonably complete list as well.
Not all listed libraries from the list qualify. Specifically:
- Some libraries included use another Json parser: for example, both XStream and Jettison use the "json.org" reference implementation as the underlying parser
- Some libraries can only generate Json, not parse it (such as flex-json
- One otherwise decent-looking candidate (Google-gson) only implements data-bin ding interface, which is which might may be a decent Json processing package only seems to implement data binding functionality, but not streaming or tree-based alternative (I am hoping to include it in the data-binding tests)
Given this, here are the contestants:
- Json.org reference implementation: the "standard" choice most developers start with
- Json Tools from Berlios (full-featured, well-documented)
- Json-lib (another fairly full-featured package)
- Json-simple from Google code
- StringTree JSON (delightfully compact code; alas very simplistic regarding well-formedness checks)
- Jackson (the reigning champion from the last test), version 0.9.8
Of these, all implement a tree-model; some also implement data binding (json-tools and Jackson at least), but only Jackson appears to implement pure streaming interface. For this reason, there are 2 tests for Jackson: one using Tree model, the other streaming API.
4. Results
After letting Japex churn through the test for almost an hour, we get the actual results. Full result data and graphs can be found here. (also: here are result from another test run (this one with a more modern dual-core system). Both runs are on a Linux desktop machine, using a recent JVM (1.6.0 update 10 or 12)
But here is the main graph (from the first test run) that summarizes results:
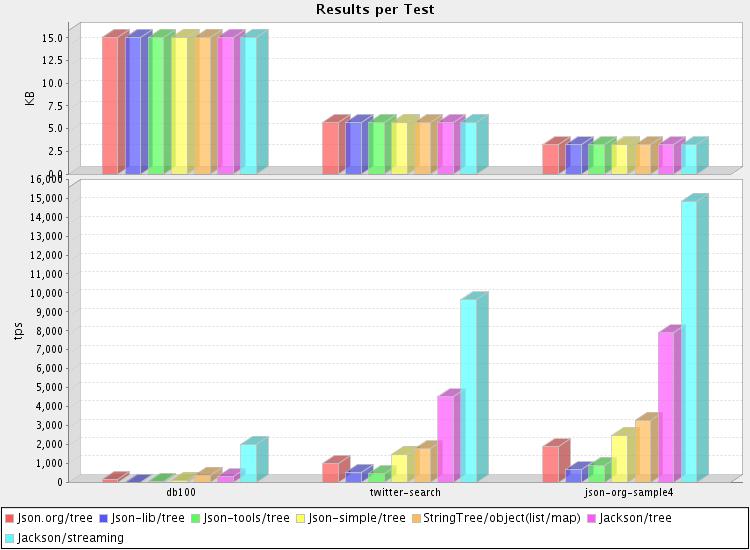
It looks like Jackson is still rather more efficient at parsing than the rest: not only is the core streaming parser very fast, even the tree-based alternative does quite well. In fact, graph readability suffers a little bit from Jackson's dominance.
As for the rest, StringTree parser performs a bit better than the others. But the biggest surprise may be the fact the reference implementation is faster than most alternatives; despite the claims made for these alternatives (I have yet to find a library that doesn't claim to be light-weight and fast :) ). In a way that's good -- at least most developers are not using the slowest available parsers.


