One commonly occuring them on discussions on merits (or lack thereof) is
the question "but does the size matter". That is: while textual formats
are verbose, they can be efficiently compressed using common every day
algorithms like Deflate
(compression algorithm that gzip
uses). From information theory standpoint, equivalent information should
compress to same size -- if one had optimal (from information theory
POV) compressor -- regardless of how big the uncompressed message is.
And this is quite apparent if you actual test it out in practice: even
if message sizes between, say, xml, json and binary xml (such as Fast
Infoset) vary a lot, gzipping each gives rougly same compressed file
size.
But what is less often measured is how much actual overhead does
compression incur; especially relative to other encoding/decoding and
parsing/serializing overhead. Given all advances in parsing techniques
and parser implementations, this can be significant overhead:
compression is much more heavy-weight process than regular streaming
parsing; and even decompression has its costs, especially for
non-byte-aligned formats.
So: I decided to check "cost of gzipping" with Jackson-based
json processing. Using the same test suite as my earlier JSON
performance benchmarks, I got following results.
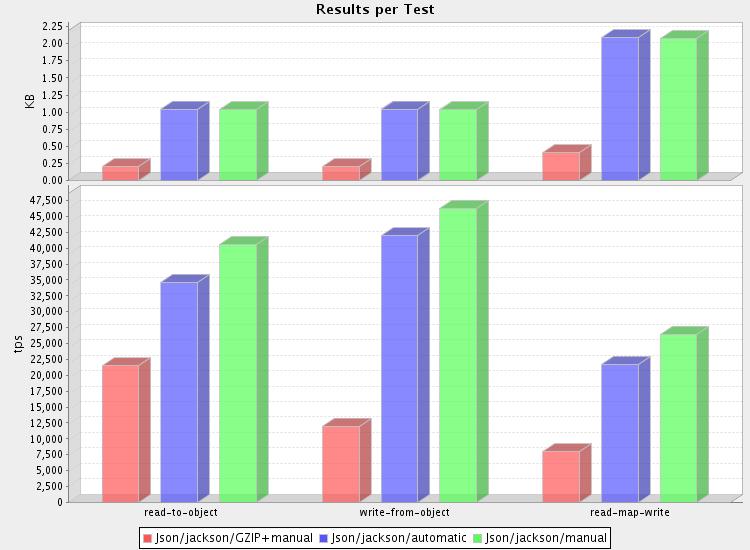
First, processing small (1.4k) messages (database dumps) gives us
following results:
(full results here)
and medium sized (16k): (full
results)
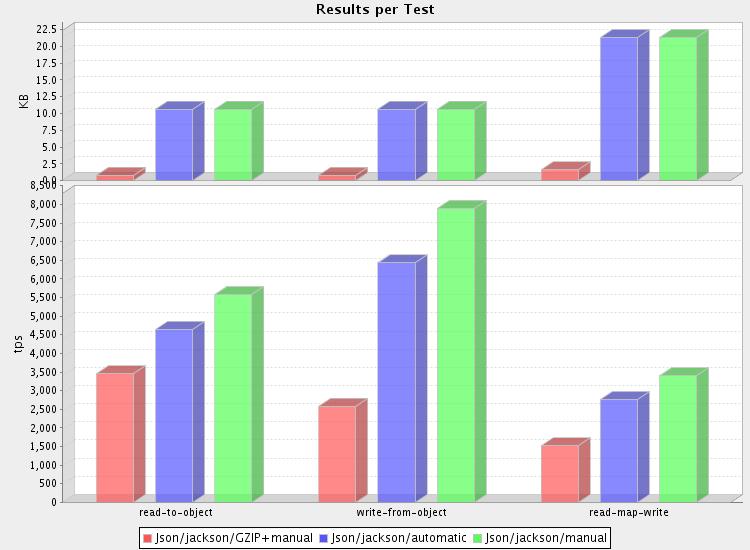
(just to save time -- results using bigger files gave very similar
results as medium ones, regading processing speed)
So what is the verdict?
1. Yes, redundancies are compressed away by gzip
Hardly surprising is the fact that JSON messages in this test compressed
very nicely -- result data (converted from ubiquitous "db10.xml" etc
test data) is highly redundant, and thereby highly compressible.
And even for less optimal cases, just gzipping generally reduces message
sizes by at least 50%; similar to compression ratios for normal text
files. This is usually slightly better than what binary formats
achieves; oftentimes even including binary formats that omit some of
non-redundant data (like Google Protococol Buffers which, for example,
requires schema to contain field names and does not include this
metadata in message itself).
2. Overhead is significant, 3x-4x for reading, 4 - 6x for writing
But it all comes at high cost: overhead is highest for smallest
messages, due to significant fixed initialization overhead cost (buffer
allocations, construction of huffman tables etc). But even for larger
files, reading takes about three times as long as without compression,
if we ignore possible reading speed improvements due to reduced size.
And the real killer is writing side: compression is the bottleneck, and
you'll be lucky if it takes less than five times as long as writing
regular uncompressed data.
3. Is it worth it?
Depends: how much is your bandwidth (or storage space) worth, relative
to CPU cycles your programe spends?
For optimal speed, trade-off does
not seem worth it, but for distributed systems costs may be more in
networking/storage side, and if so compression may still pay off.
Especially so for large-scale distributed data crunching, like doing big
Map/Reduce (Hadoop) runs.
Or how about this: for "small" message (1.4k uncompressed), you can STILL
read 22,000, write 12,000, or read+write 8,000 messages PER SECOND
(per CPU). That is, what, about 7900 messages more processed per second
than what your database can deal with, in all likelihood. Without
compression, you could process perhaps 14,000 more messages for which no
work could be done due to contention at DB server, or some other
external service... speed only matters if the road is clear.
Yes, it may well make sense even if it costs quite a bit. :-)
4. How about XML?
If I have time, I would like to verify how XML+GZIP combination fares: I
would expect same ratios to apply to xml as well. The only difference
should be that due to somewhat higher basic overhead, relative
additional overhead should be just slightly lower. But only slightly.


