JSON data binding performance: Jackson vs Google-gson vs BerliOS JSON Tools
UPDATED: see a more up-to-date version here
Earlier I have published some results on performance of "simple" JSON parsing -- simple meaning that processing is manual, to allow for processing JSON using wide variety of Java+JSON tools available. This includes processors from ultra-fast streaming processors (like Jackson) all the way to "good old JSON.org" parser. But it also excluded at least one potentially good tool (google-gson), since it requires "untyped" access, ability to traverse arbitrary JSON structure for testing.
Also: more and more access is nowadays done using a more convenient class of tools, called data binding (or mapping; or sometimes serialization) tools (libraries, packages). In such cases application just asks library to convert JSON to a Java Object (or vice versa), and that's about it. Very convenient; especially for strongly typed web services.
So, with that background, let's see what are performance characteristics of available tools.
1. JSON Data Binding: Contestants
Now, list of tools that allow doing is somewhat limited: I am aware of following:
- Jackson
- Json-tools (oldest such Java tool, as far as I know)
- Google-gson
Given that all of them can do conversions with similar ease (at least for simple Java types), is there much difference in performance? To figure this out, I will be using somewhat incorrectly named StaxBind (really, it should be renamed PojoBind or something) sub-project of Woodstox. Data to bind is a simple rendition of tabular data, with List of beans that contain personal information (name, address and so on); document size (for this test) being about 2 kilobytes.
2. Results!
And yes, indeed, results look vaguely familiar (see here, for example). Considering the "bigger is better" aspect -- value measured, "tps", is number of documents read, written, or read-modify-written per second -- difference from slowest (google-gson) to fastest (Jackson) is a solid order of magnitude.
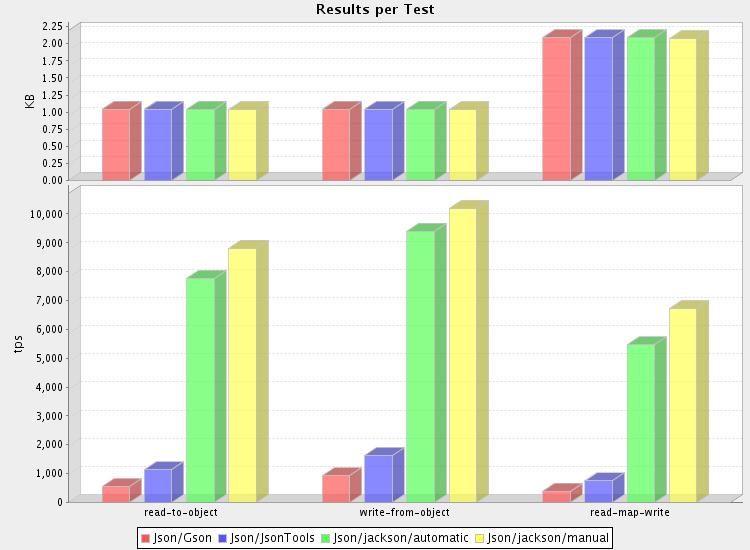
Looks like Jackson still the King of JSON, regarding processing speed -- and by ridiculously high margin too... If you are already a Jackson user, you may want to congratulate yourself on choosing a very efficient (even green! save those cycles!) tool. A pat on your back might be warranted as well. To put performance in perspective; being able to read ten thousand 2k documents per second (throughput of about 20 megabytes per second), on an almost obsolete AMD Athlon based PC (my home PC) is not too shabby; and all this without little if any glue code.
Actually, as you can see, there is one (and only one!) thing faster than Jackson Data Mapper: "raw" hand-written data mapper. And even that is just a bit faster; probably only worth the extra hand-written code for high-volume use cases, or where number of POJO types is very limited.
3. Some details
Given the big difference in perceived performance, avid readers might be interested in reproducing results, or at least perusing source code. All code is within "staxbind" module in the primary Codehaus Woodstox SVN repository., and author (me!) can be contacted for more details (for some reason Codehaus interface makes access sometimes bit harder than needs be), questions and suggestions.
But there is nothing particularly complicated about code; here's how core methods for tested packages actually look like (interfaces are defined by StaxBind package itself; template T translates to "DbData" (POJO type)).
3.1 Jackson test code
Jackson code is simplest of alternatives, as it supports direct streaming access
public class StdJacksonConverter extends StdConverter
{
ObjectMapper mapper = new ObjectMapper();
//...
public T readData(InputStream in) throws IOException {
return _mapper.readValue(in, _itemClass);
}
public int writeData(OutputStream out, T data) throws Exception {
JsonGenerator jg = _jsonFactory.createJsonGenerator(out, JsonEncoding.UTF8);
_mapper.writeValue(jg, data);
jg.close();
return -1;
}
}
3.2 Json-tools test code
Test code here needs a couple of more lines, since there is no way to directly go from POJOs to stream/String and back. But nothing excessive.
public class StdJsonToolsConverter extends StdConverter
{
final JSONMapper _mapper = new JSONMapper();
//...
public T readData(InputStream in) throws Exception {
// two-step process: parse to JSON value, bind to POJO
JSONParser jp = new JSONParser(in);
JSONValue v = jp.nextValue();
return (T) _mapper.toJava(v, _itemClass);
}
public int writeData(OutputStream out, T data) throws Exception {
JSONValue v = _mapper.toJSON(data);
String jsonStr = v.render(false);
OutputStreamWriter w = new OutputStreamWriter(out, "UTF-8");
w.write(jsonStr);
w.flush();
return -1;
}
}
3.3 Google-gson test code
This test code is bit shorter than Json-tools one, since package does not use intermediate tree form. Surprisingly this does not seem to translate to better performance, as the package ends up taking its time doing conversions. On positive note, there should be plenty of room for improvement in this area...
public class StdGsonConverter extends StdConverter
{
final Gson _gson = new Gson();
public T readData(InputStream in) throws IOException {
return _gson.fromJson(new InputStreamReader(in, "UTF-8"), _itemClass);
}
public int writeData(OutputStream out, T data) throws Exception {
OutputStreamWriter w = new OutputStreamWriter(out, "UTF-8");
this._gson.toJson(data, w);
w.flush();
return -1;
}
}


