JSON data binding performance (again!): Jackson / Google-gson / JSON Tools... and FlexJSON too
(note: this is a follow-up on an earlier measurements)
1. A New Contestant: FlexJson
After realizing that FlexJson is actually capable of both serialization and deserialization (somehow I thought it would only serialize things), I decided to add it as the fourth contestant in the "full service Java/JSON data binding" category of tests.
Initially I was bit discouraged to find that it makes one rookie mistake: assumes that somehow JSON comes in (and goes out) as Java Strings. But aside from this glitch, package actually looks quite solid -- and its exclusion/inclusion mechanism looks interesting. Maybe not exactly my cup of joe (if it was, after all, Jackson API would look more like it does), but a viable alternative. And I can see how ability to prevent deep copy would come in handy sometimes. And finally, some of the features actually exceed what Jackson can currently do, regarding polymorphic deserialization (since FJ includes class name by default, I assume it can do it) and some level of cyclic-dependency handling (ignoring serialization of cyclic references at least).
So let's see how "rookie" (yes, I know, it's not exactly a new package, just new addition to the test) fares...
2. Test setup
Tests are run using nice Japex performance test framework, running on my somewhat old AMD work station (~1700 Ghz Athlon -- someone needs to click on those right-hand-side ads to get me a new performance-testing work station! :-) ).
Input data used consists of serialization of tabular data (database dump, good old "db100.xml" used by countless xml tests), converted to Java POJOs, and then to individual data formats (here as JSON, but can be tested as XML and whatnot). Document size is 20k in XML, and slightly less in JSON (about 16k). It would be easy to run using other data sets, but in the past, performance ratios for 2k, 20k and 200k documents have not had radical differences, so 20k one seems like a reasonable choice (but note that the earlier benchmark did in fact use 2k documents, so actual numbers do differ).
Test project itself, "StaxBind" is still in Woodstox SVN repository, accessible via Codehaus SVN page. (one of these days I should just create a Github project -- but not today).
Versions of JSON processing packages are as follows:
- Jackson 1.2.0
- Google-gson 1.4
- Json-tools-core 1.7
- Flexjson-1.9.1
Code for each library is using default settings, and using what appears as the most efficient interface, for cases where transformations are from byte streams on server side (byte streams in, byte streams out).
3. Results
First things first: here's the money shot:
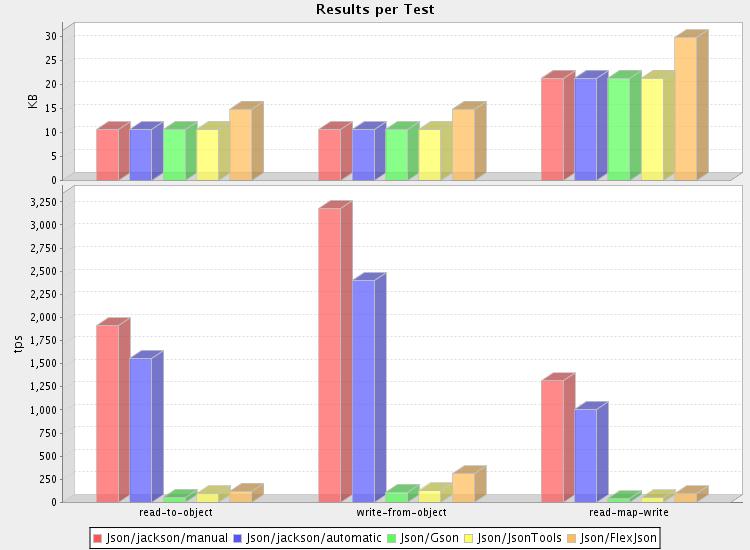
(or check out the full results for details)
Another way to represent results is by showing performance ratios, using the slowest implementation as base line (TPS == transactions per second; number of times a 20k document is read, written, or both):
(note: Jackson/manual is omitted since it is hand-written (if simple) serializer/deserializer, and there are no direct counterparts for other packages -- while it would give even bigger faster-than-thou ratio, it wouldn't be a fair comparison)
| Impl | Read (TPS) | Write (TPS) | Read+Write (TPS) | R+W, times baseline |
|---|---|---|---|---|
| Jackson (automatic) | 1599.272 | 2463.097 | 1033.809 | 25.6 |
| FlexJson | 125.277 | 125.277 | 94.904 | 2.35 |
| Json-tools | 94.051 | 126.954 | 49.008 | 1.2 |
| GSON | 56.58 | 112.455 | 40.38 | 1 |
So looks like our "new kid on the block" manages to outperform the other two non-Jackson JSON processors here. And at least get within an order-of-magnitude with Jackson... :-)
4. Musings
So it turns out that despite its interfacing (those String/byte conversions), Flexjson package manages to work more efficiently than some other packages that claim "simplicity and performance". And this without actually claiming to be particularly performant, but rather focusing on design of API and ease-of-use aspects. Pretty neat, I respect that.
5. Next?
My current main interest (with respect to performance issues) lie in the area of compressing data for transfer: after all, most of the time there is relative abundance of CPU power compared to available network and I/O bandwidth. This means that trading some CPU (needed for compression and decompression) seems like a bargain for many use cases.
But on the other hand, as we saw earlier, the question is "how much is too much". And that's where my new favorite simple-and-fast algorithm, LZF, comes in. But that's a different story.


